Econometrica, Vol. 87, No. 1, January 2019, pp. 217-253.
The copyright to this Article is held by the Econometric Society. It may be downloaded, printed and reproduced only for educational or research purposes, including use in course packs. No downloading or copying may be done for any commercial purpose without the explicit permission of the Econometric Society. For such commercial purposes contact the Office of the Econometric Society (contact information may be found at the website http://www.econometricsociety.org or in the back cover of Econometrica). This statement must be included on all copies of this Article that are made available electronically or in any other format.
CPS Data, variables and sample restriction
Data was taken from the Annual Demographic Surveys (March CPS supplement) conducted by the Bureau of Labor Statistics and the Bureau of the Census. This survey is the primary source for detailed information on income and work experience in the United States. A detailed description of the survey can be found at: https://www.bls.gov/cps/. Our data, for the years 1962-2014, was extracted using the IPUMS. The sample is restricted to white civilian adults, ignoring armed forces and children. In both section 2 and in estimation we define unmarried as including separated, widowed, divorced and never married. We divided the sample into five education groups: high school dropouts (HSD), high school graduates (HSG), individuals with some college (SC), college graduates (CG) and post-college degree holders (PC). In order to construct the education variable, we use the variable “educ” constructed by IPUMS. Wages are multiplied by 1.75 for top-coded observations until 1995. Nominal wages are deflated using the Personal Consumption Expenditure (PCE) index from NIPA table 2.3.4 (http://www.bea.gov/national/nipaweb/index.asp). Since wages refer to the previous year, we use PCE for year t-1 for observations in year t and therefore all wages are expressed in constant 2009 dollars. In order to construct couples, we kept only heads of households and spouses (i.e. no secondary families were used) and dropped households with more than one male or more than one female. We then merged women and men based on year and household id and dropped problematic couples (with two heads or two spouses, with more than one family or with inconsistent marital status or number of children).
Health Data
Data was taken from the IHIS (integrated health interview series) at Minnesota. The survey contains a subjective health index that can get 5 values: Excellent, Very Good, Good, Fair, Poor. We created a new 3 values variable: Good, Fair and Poor. We then calculated the cumulative distribution of this new variable by cohort, gender and age, using the following STATA do file.
|
· code for constructing the health distribution used in the paper |
Taxes Data
The individuals in the model get a gross wage offer, yet, their decisions are based on their net income. After the realization of the wage offer is known, we calculate the household gross income and then calculate the net income of the household, taking into account the tax system in the current year, whether it’s a single household or a couple (we assume married couples jointly pay their taxes). To simplify the model, we assume full forecast of the tax system. To calculate the net income of the household/individual, we collected historical data from 1950-2017 on the following:
1. Federal Individual Income Tax Rates History (https://taxfoundation.org/federal-tax/individual-income-payroll-taxes)
2. Standard deductions history (http://www.taxpolicycenter.org/statistics/standard-deduction)
3. Personal and Dependents Exemption (https://www.irs.gov/publications/p17/ch03.html)
4. Earned Income Tax Credit Parameters (http://www.taxpolicycenter.org/statistics/eitc-parameters)
We programmed a “tax calculator” function, were the inputs are gross income, marital status, number of children and the year and the output is net income. The program uses the actual tax brackets and marginal tax rate, the full structure of the EICT and deduction and exemption that varies by the marital status and the number of children. We assume that the maximum number of tax brackets is 10 (For some years before 1986, there were more than 10 tax brackets, so we unified similar tax brackets, i.e. instead of having two tax brackets, one with 49% marginal tax rate and one with 50%, we unified the two into one tax brackets). The tax brackets and marginal rate that were used in the model together with the full historical data on EICT, deductions and exemptions can be find below:
|
· tax brackets, marginal rates, deductions, exemptions and EICT data |
Welfare Data
The welfare payment by number of children for single mothers is given by the function 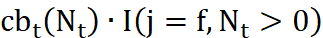 as in equation (13). It is estimated separately using the data on welfare from the CPS which is captured by the variable INCWELFR in IPUMS. This variable indicates how much pre-tax income (if any) the respondent received during the previous calendar year from various public assistance programs commonly referred to as “welfare”. We adjust for the effects of inflation using PCE (personal consumption expenditure) deflators – NIPA Table 2.3.4, as we did with all wages in our sample. We then run a regression of the real annual welfare payment as a function of the number of children for non-married, unemployed women with children who get welfare benefits. We run the regression separately for each cohort. The STATA code for welfare payments for single mothers (2009 prices):
as in equation (13). It is estimated separately using the data on welfare from the CPS which is captured by the variable INCWELFR in IPUMS. This variable indicates how much pre-tax income (if any) the respondent received during the previous calendar year from various public assistance programs commonly referred to as “welfare”. We adjust for the effects of inflation using PCE (personal consumption expenditure) deflators – NIPA Table 2.3.4, as we did with all wages in our sample. We then run a regression of the real annual welfare payment as a function of the number of children for non-married, unemployed women with children who get welfare benefits. We run the regression separately for each cohort. The STATA code for welfare payments for single mothers (2009 prices):
Data for Section II: Key Patterns in the Data
|
· wages |
Estimation Results